HERO-Deploy
- 👉Easy adjustment of parameters: use yaml for the management of different task parameters.
- 💪Suitable for multiple architectures: Onnx and OpenVINO deployments are currently supported.
- 😄High scalability: managing different models with different deep learning tasks as python packages.
- 🤗Very user-friendly: provides a framework for a variety of models, just change the path of the model in yml and you can use it directly!
Project Introduction
A generalized deep learning model deployment framework. Model deployment is greatly facilitated by highly scalable templates. Currently available OpenVINO and ONNX Runtime. This project is mainly to realize the deployment of various types of deep learning models, pytorch training out of the .pt format model files often can not be directly deployed in the c++ , resulting in the model can not be used in the edge computing platform to use, usually need to be converted to onnx format to use, the mainstream deployment methods mainly onnxruntime, openvino, TensorRT. Regardless of which scheme to deploy, the general process can be divided into model preprocessing, model inference, model post-processing of the three parts. The project aims to build a common framework to provide a convenient way to allow different models can be deployed through different deployment tools to achieve rapid deployment. It also has features such as effect visualization and model quantification.
Project Workflow
The project process is shown in the figure below:
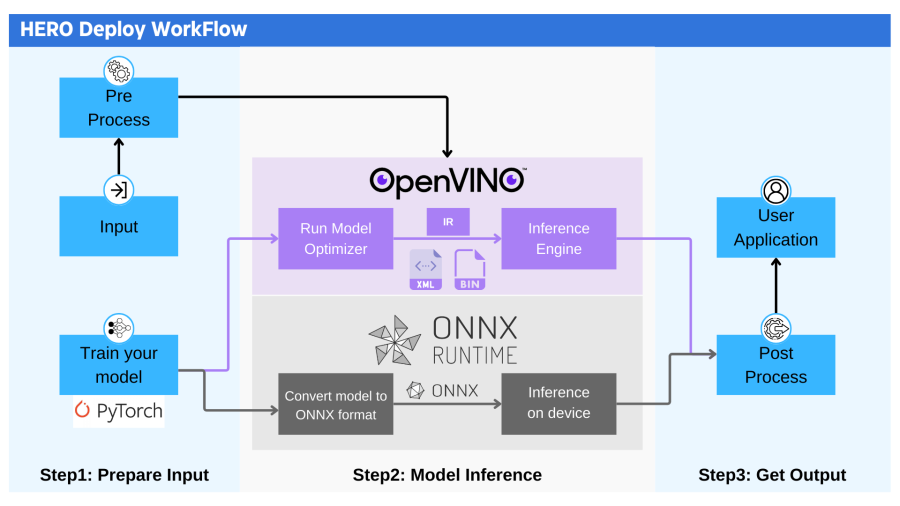
The overall process of the project is divided into three parts: prepare input, model inference, and get output. All model deployment frameworks can adopt this process. Currently, onnx runtime and OpenVINO are supported.
Preparing the input part to do is twofold, on the one hand, first you need to build your network and complete the training, to get the .pt file to be deployed, on the other hand, you need to confirm that your input data need to be what preprocessing (image size, input data type, etc.), the current program has been configured with common preprocessing functions, if you need to add new preprocessing functions can also be achieved on their own by modifying the Preprocess part of the code to achieve.
The first thing you need to do in the model inference section is to select the inference platform you want to use, and then set up the parameters related to the inference process (model paths to be deployed, inference optimization, etc.). When using OpenVINO for inference, it should be noted that you can choose to convert your .pt format model file to onnx format and then transform it to IR format for inference under OpenVINO, or you can choose to use the onnx format file directly for inference.
The post-processing process is the biggest difference between all the models deployed, due to the different output data formats of different models, you need to decode the data according to your actual needs, so please note that the code in this part of the code in most cases need to go to make some changes. At this point the entire reasoning process has been completed, you can also choose to go to the model effect visualization and model quantization and other functions.
Project usage Scenario
In our robot team, we need to train different deep learning models for different computer version tasks in the competition. Currently, the deep learning framework used in our team is PyTorch, and under normal circumstances, the testing of the models is carried out in Python, but in RoboMaster, due to the characteristics of the competition, the speed of the models is extremely demanding, so we need to deploy our models in c++ through the deployment tool to increase the speed of our models and improve our robot’s performance in this way.
Currently in our team, the models that have been put into use are armor classification model, four-point armor object detection model, Top-Down armor key point detection, Top-Down power rune fan blade key point detection, these models need to be deployed, and in the actual use of the process, although the structure of the different models is different, but the deployment process of the code multiplication is very large, so the use of HERO Deploy can be a very good way to improve the efficiency of our model deployment and testing, and shorten the development cycle.
In addition, through the structure of HERO Deploy and the convenient parameterization function, I believe that in the future we can also apply the framework to other practical projects outside of the competition, so that we can explore the relevant technology.